
Principia #1: Fiabilidad (Reliability)
La fiabilidad no es ni gratis ni infinita

Se me ha ocurrido empezar una serie de artículos para definir algunos términos del campo de la ingeniería del software. No es que me haya dado por convertirme en académico de la RAE, ¡qué va! Sino que muchas veces utilizamos de forma ambigua o incorrecta algunos términos —yo el primero—, y creo que puede ser interesante explicar, al menos como yo lo interpreto, qué significan y qué implicaciones tienen. A esta serie la voy a llamar Principia (principios), en honor a este Substack y a Isaac Newton.
Y qué mejor manera de empezar esta serie que con la fiabilidad (reliability).
- f. Cualidad de fiable.
- f. Probabilidad de buen funcionamiento de algo.
— RAE: fiabilidad

A simple vista parece que no hay mucho que explicar. Una cosa es fiable cuando es improbable que deje de funcionar. Venga, ¡hasta luego!
Pero en el campo de la ingeniería del software, el término fiabilidad adquiere un significado más específico, con consecuencias importantes. Se refiere a la capacidad de un sistema para funcionar correctamente bajo condiciones adversas durante un período de tiempo determinado. Es decir, no solo que funcione bien en condiciones ideales, sino que también lo haga (de manera decente) cuando las cosas se ponen feas.
Un detalle en la definición de la RAE que me gusta es la expresión “probabilidad de buen funcionamiento”. Porque la fiabilidad no es una propiedad absoluta que se tenga o no. No existe un sistema 100% fiable. Siempre hay una probabilidad, por pequeña que sea, de que algo falle. La pregunta, por tanto, no es si un sistema es fiable o no, sino cuán fiable es.
Un error común a la hora de diseñar o programar sistemas es no considerar cómo se comportarán ante situaciones adversas: fallos de hardware, picos de carga, caídas del proveedor, ataques DDoS o simples errores humanos. Un sistema fiable debe ser capaz de mantener su funcionalidad o degradarse de forma controlada sin colapsar por completo. Es decir, el no funcionamiento también debe estar diseñado.
Y aquí entra un concepto relacionado con la fiabilidad, aunque más amplio: la resiliencia. Mientras la fiabilidad busca que algo no falle, la resiliencia asume que fallará, pero sabrá recuperarse o mantener el servicio de alguna forma. En realidad, lo que buscamos son sistemas resilientes. Porque la realidad es que todo fallará en algún momento. La cuestión está en cómo lo hará.
El hecho de que la fiabilidad sea una probabilidad nos permite cuantificarla con métricas como:
MTBF (Mean Time Between Failures)
MTTR (Mean Time To Repair)
Disponibilidad (Uptime): porcentaje de tiempo en el que el sistema está operativo.
En otro artículo definiremos en profundidad el concepto de disponibilidad (availability). Aquí utilizo solo una de las formas de calcularla.
Por ejemplo, si un servicio tiene un MTBF de 1000 horas y un MTTR de 1 hora, su disponibilidad aproximada será del 99,9 %. Esto lo calculamos con la fórmula:
Reducir ese tiempo medio de reparación (MTTR) de una hora a unos pocos minutos, o evitar la recurrencia de los fallos (MTBF), puede multiplicar el coste de implementación y de operación. Y esta también es una de las claves a tener en cuenta para entender la fiabilidad que podemos permitirnos: el coste no crece de forma lineal.
Pasar de un 99% a un 99,9% de disponibilidad puede resultar relativamente asumible. Pero pasar de 99,9% a 99,99% o 99,999% puede requerir inversiones desorbitadas e insostenibles para muchas empresas: redundancia geográfica, replicación síncrona, failover automático, circuit breakers, colas persistentes, reintentos con backoff exponencial, despliegues blue/green, e incluso chaos engineering para probar que todo eso realmente funciona.
Y no solo hablamos de resiliencia a nivel de infraestructura, sino también de mejorar los procesos de calidad y de desarrollo de software: pruebas automatizadas, revisiones de código serias, análisis estático de código, mecanismos para graceful degradation, etc. forman parte de la construcción de un sistema fiable. La fiabilidad no se puede añadir al final, como accesorio, sino desde el principio.
Hay estudios que cuantifican este fenómeno. Cuanto más fiable es un sistema, menor es el coste de mantenimiento (porque fallará menos), pero mayor es el coste de implementar y operar las medidas necesarias para alcanzar ese nivel. Y viceversa: cuanto menos fiable sea, mayor será el coste en mantenimiento (más incidencias y correctivos), en tiempo y en reputación.
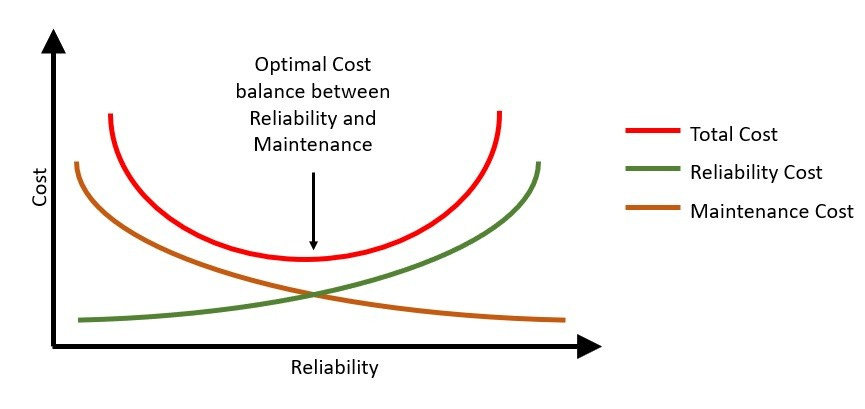
Existe un punto medio teórico —el óptimo entre coste y fiabilidad— que cada empresa debe elegir según la naturaleza de su negocio, sus usuarios y su presupuesto. Ese punto de equilibrio también es una decisión de riesgo para la empresa. En el libro de SRE de Google, en el capítulo Embracing Risk, se dice que no se trata de eliminar los fallos, sino de aceptar que existen, comprender su impacto y gestionarlos de forma consciente. La fiabilidad no consiste en perseguir el 100%, sino en elegir cuánto riesgo puedes asumir.
Y si el argumento técnico no convence en las altas esferas, el económico sí suele convencer. Según estudios, el coste medio de una caída de servicio ronda los 9000 dólares por minuto en organizaciones grandes. En empresas como Amazon, una hora de inactividad puede traducirse en pérdidas por millones (ya veremos por cuánto le sale la cuenta a AWS la caída reciente en us-east-1). Y en sectores como aerolíneas o banca los fallos pueden generar daños de reputación irreversibles.
La fiabilidad no se mide solo en nueves. También en euros, dólares… y confianza de los usuarios.
La fiabilidad no es gratuita. Requiere inversión, procesos y disciplina. Pero ignorarla tiene un coste aún mayor, que es la pérdida de confianza de los usuarios. Y esa, una vez perdida, no hay redundancia que la repare.
¡Muchas gracias por leerme!